Saiba como recuperar os dados perdidos de um celular, cartão de memória, disco rígido, pendrive, SSD etc.
Entenda o que não fazer, para melhorar as suas chances de resgate.

Saiba como recuperar os dados perdidos de um celular, cartão de memória, disco rígido, pendrive, SSD etc.
Entenda o que não fazer, para melhorar as suas chances de resgate.

Veja como é fácil inserir informações EXIF nos nomes dos arquivos exportados do DarkTable
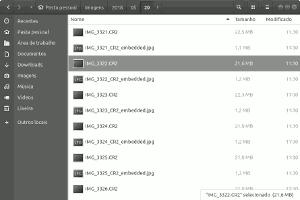
Você está tendo problema com arquivos de imagem RAW (crus) corrompidos ou danificados durante a transferência da câmera para o computador. Confira algumas dicas para lidar com este problema.
O Grsync é uma alternativa para quem deseja transferir arquivos, com a segurança e a versatilidade do rsync e a beleza da interface gráfica.

Como realizar pesquisas dentro de arquivos .doc da linha de comando do linux, com o uso do comando grep aliado ao catdoc.