Saiba como recuperar os dados perdidos de um celular, cartão de memória, disco rígido, pendrive, SSD etc.
Entenda o que não fazer, para melhorar as suas chances de resgate.

Saiba como recuperar os dados perdidos de um celular, cartão de memória, disco rígido, pendrive, SSD etc.
Entenda o que não fazer, para melhorar as suas chances de resgate.
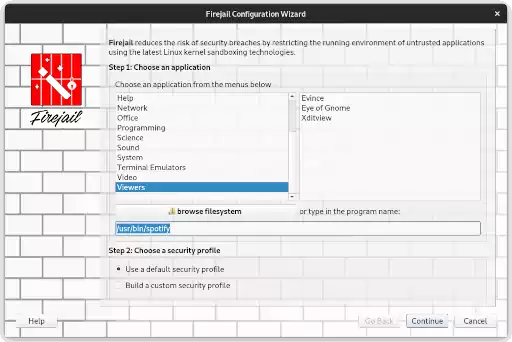
Use o Firejail, para executar aplicativos e processos, em segurança, dentro de caixas de areia (sandboxes) e isolados do restante do seu sistema.
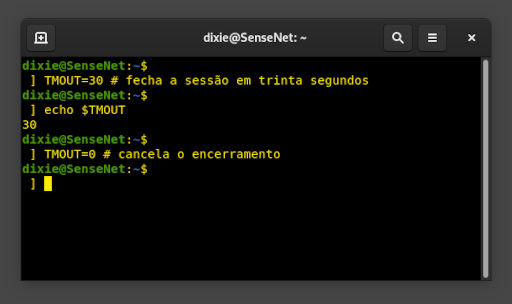
Como encerrar uma sessão no Bash shell após um tempo (em segundos), predeterminado.
Estes 3 atalhos de teclado vão ajudar você a se desenrolar ainda mais rápido no terminal, poupando alguns minutos no seu dia a dia.

Use o top, no Linux, para descobrir processos que estão consumindo mais processamento e veja como lidar com eles, usando kill e renice.